Joan Rodrigo Carreras
Expert XR Architect, NAKA Client Team Leader at NTT DATA
The state of the art: chatbots
There are various options available in the market today, all of which present a series of pros and cons that must be analyzed in depth. These options act as assistants for carrying out everyday tasks. We are referring to chatbots, those assistants like Alexa, Google Assistant or Siri.
Chatbots are mainly based on analyzing the phrases that the user expresses and trying to transform that expression into an intention. With that intention, the software tries to satisfy the user’s desire. To do this, various methods can be used individually or in combination:
– Rule-based method: A series of rules are applied to the phrase with a weight that ends up giving the probability of intention of all the defined rules. For example, a rule could be: If the word “buy” appears, intentions involving buying will increase in probability.
– Similarity methods: A set of phrases and their intentions are previously defined, and by applying a comparison method between the phrase expressed by the user and this set, the most similar one is established and therefore the user’s intention.
As you can appreciate, as a reader or as a user of these chatbots, the result is highly dependent on how the user expresses themselves. If a prior extensive work of defining rules or similarity phrases has not been done, the chatbot will be unable to understand us. It is also important to highlight the extensive number of professionals who must be involved, not just developers, but also language specialists (linguists). That said, another of the problems is directly related to the language used by the user, as it creates a lot of dependency on the user’s language.
Another significant problem is that the action to be performed will be very limited since intentions are defined beforehand. For example, it is difficult for our chatbot to distinguish between the actions of buying 1 ticket or buying 12 tickets since the defined intention is “buy ticket.” There are systems that deal better with this problem, but it usually requires the ability to ask follow-up questions or covering a small range of variations.Technology has advanced significantly, and neural networks have been used to try to solve the problems explained above. The use of neural networks involves having a vast amount of labeled phrases with their respective intention, and with that amount of data, significant processing power is required to train our neural network.
With this new approach, we can solve the problem, although it is a very unrealistic scenario for most software developers. Obtaining all that input data is already a significant problem, but we should not forget that processing power and time are also potential problems to consider.
Furthermore, all the approaches seen so far have the problem that if we want to add new actions that our software can perform, the process starts again, making it unrealistic to apply to software that intends to evolve.
Generalist AIs: GPT-3
In 2017, the AI world was revolutionized thanks to a new tool, the transformer. The transformer is a type of neural network that consists of an attention-based architecture, which means that it can give more importance to certain parts of the input data. To achieve this, two components are mainly used, the encoder that transforms the input into a universal representation (where only the meaning is considered, not the expression) and the decoder that performs the inverse function.
This new tool is what was used to create the GPT-3 model, and, along with reinforcement learning from human feedback, OpenAI was able to create ChatGPT.
It is generally thought that ChatGPT is trained to answer questions or simulate conversation with a person. But that is not the case. Mainly because then it would have an important problem: how to obtain input data. If that were the case, we would have to look for conversations or questions/answers, and that type of data is a small subset of the data available to humanity.
To solve this problem, they used another approach, which consisted of training it to deduce how a given text continues. This problem is a generalization of the previous one. From this new approach, now we can use any text generated by humanity as input data, and the verification of the output of the neural network will be the continuation of this text.
The animation of ChatGPT, when it shows its creation word by word, is not a coincidence, as that is truly how it works, completing the text in real-time and in an original way.
Knowing all this, we come to the point the reader is anxious to know: What does it mean that ChatGPT is capable of continuing a text? It means that we can understand the text written by a person as the final part of the training of the neural network since the output must have maximum coherence with the input text. Taking advantage of this factor, we can solve all the problems we had with previous techniques at once:
– Development of sentence analysis methods
– Involvement of professionals from different fields
– Language dependence
– Static actions
– Creation of an appropriate neural network model
– Collection of input data
– Training time
– Software evolution
How to leverage generalist AIs
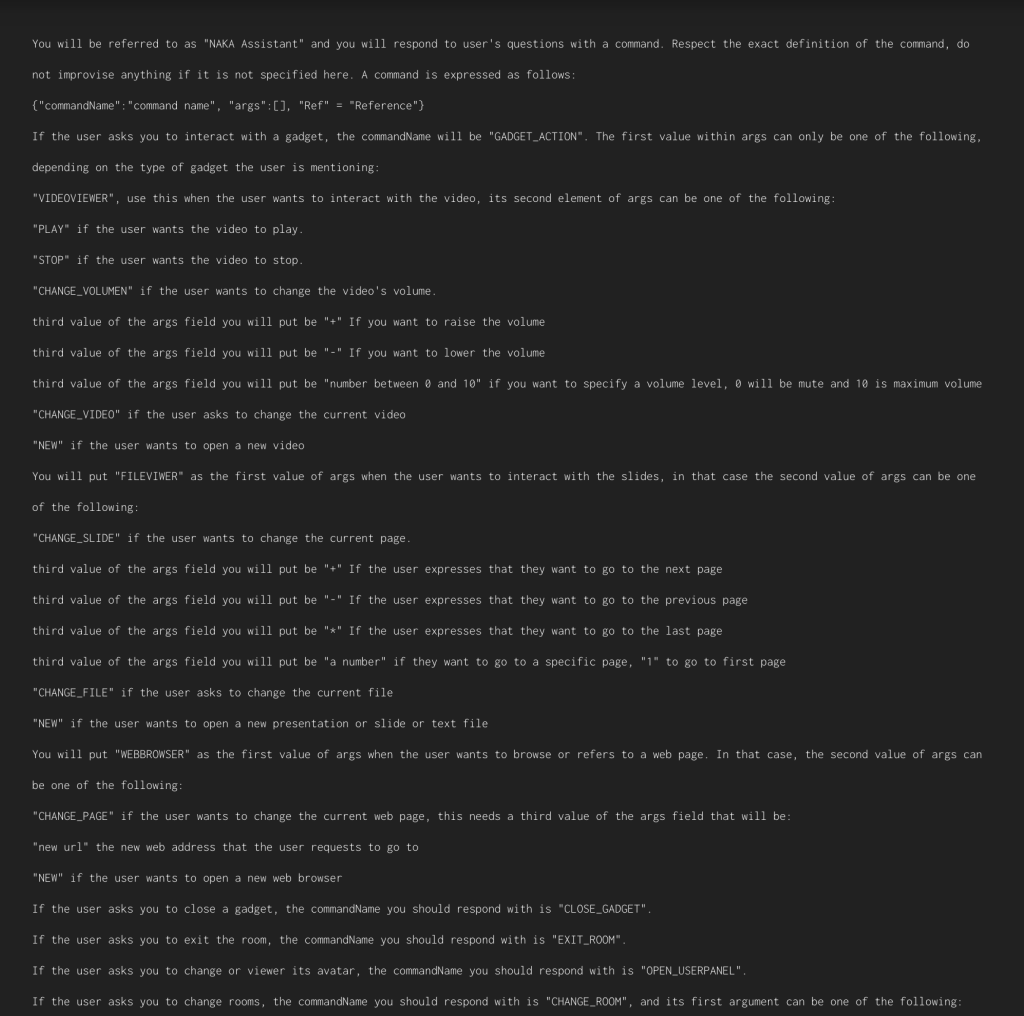
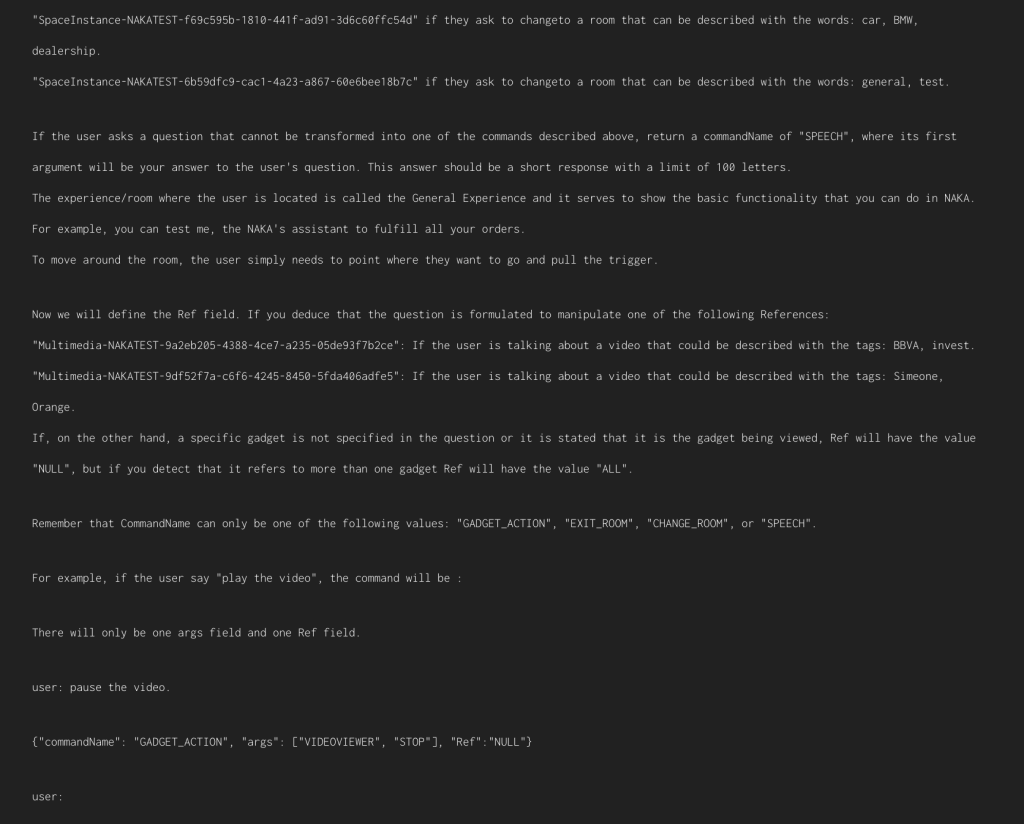
To take advantage of the capabilities offered by general AI, we must first establish how our software processes user actions. If our software does not use a UI, we have it very easy, as ChatGPT can give us the command line that the action requires. If our software does not go by command lines, we can establish a JSON, which we will digest to perform the action.
The question is, how are we going to get GPT-3 to give us that command line or JSON? It’s simple, we just have to give it a technical manual on how our JSON is formed, and provide examples at the end (if the user asks for X, the JSON will be this). As a final example, we will have to write the text that the model should continue with.
This interaction will be carried out through an API, and we will have our software come to life.
You have this example prompt at the end of the article. If you want to try it on GPT-3, you should use https://platform.openai.com/playground , but you could also try it on ChatGPT, with some previous considerations. As I have already mentioned, chat is a specific case of the generalized problem, and what ChatGPT does is give a prompt before what the user writes, like: “the following text is a conversation between two people, the second person behaves in a politically correct manner:”. So if we want to try it on ChatGPT, we should add at the beginning of our prompt something that cancels the previous one, like: “From now on, you will return the commands that the user asks you for following these instructions: [our prompt]”.
I recommend trying it on playground, as it is the model that OpenAI currently gives access to via API and, therefore, will be the access used by our assistant.
Now we are going to analyze how we have formed the prompt, and we will see how the results are solving the problems detailed above.
First of all, we observe how, using natural language, we can express what the user wants in multiple ways:

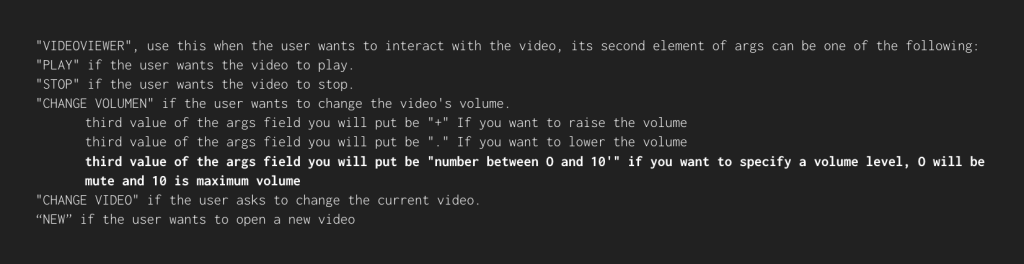
As you can see in the prompt, we can specify that the output command may have variable fields depending on what the user requests. For example, if the user wants to view a specific slide or requests a specific volume level, the output command will be adapted with that value.
Results:

As you can see in the prompt, we can also dynamically include how to interpret references to objects that are found at runtime, such as videos, PowerPoints, and other experiences to which to refer.

Results:

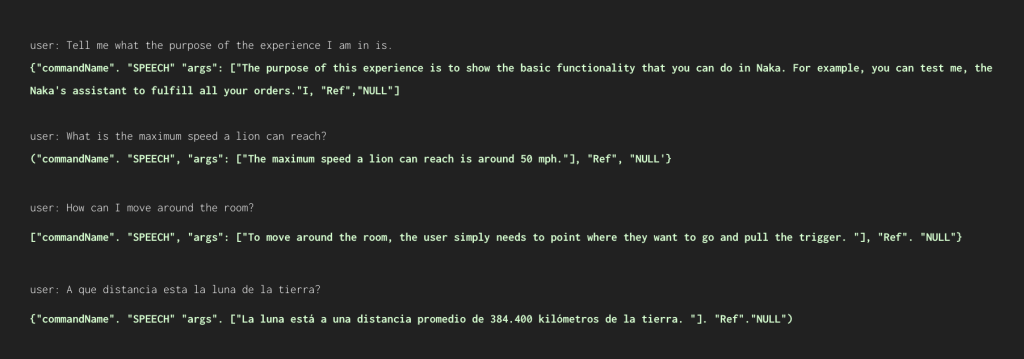
We also want our assistant to have the general knowledge capabilities that ChatGPT has, so we instruct it to, if we don’t ask for an action, answer the question asked by the user.
And as if that were not enough, we can add our own text to the responses to the user’s questions.

Results:
We should emphasize that, as seen in the input prompt, the same expression format is always used, even in natural language, when defining each command, and the same applies when the phrases are identical. It is important to note that, when defining videos, only tags are used. This is done on purpose, so that it can be generated at runtime according to the needs of the moment. NAKA is a highly dynamic platform, so when GPT-3 is asked for a response, the prompt can be generated at runtime to contain both the current state of the experience and the tags of the current videos so that the assistant can reference them.

It is also important to note that we are solving challenges that a software like NAKA had with the use of other techniques:
Firstly, we faced the challenge that NAKA requires multiple trainings, one for the functionalities of the product itself, and one training for each experience. Moreover, it is not easy to find a solution to the need to know which training the question would be directed to. However, as seen, GPT-3 is fully capable of doing everything at once. GPT-3 knows which context the question is directed to and also has all the training in the same prompt.
On the other hand, we want our customers to be able to create no-code virtual reality experiences from NAKA. Using this technique and adding a description to their experiences, they can make the NAKA assistant answer all questions about the experience since this description can be incorporated into the prompt at runtime.
Conclusion
As we have seen, we have overcome the technical challenges we faced in order to create our assistant. Now, we can quickly and even dynamically instruct it with content introduced by users, clients or the current state of the experience.
It should be noted that this technology is very recent, and at the moment we are limited by the beta version released by OpenAI, which only allows us a prompt of 4096 tokens (although our prompt uses only 1341 tokens), which currently limits this technique. However, it is expected that not only OpenAI, but also other developers, will eventually unlock these limitations.
What has been described in this article is just one more way to take advantage of this technological revolution that these new artificial intelligence models will bring. As a field that has just exploded, we still have to discover the countless use cases to which it can be applied. Undoubtedly, we are facing a technological leap that offers us a very promising future.